Like many local LLM runners, I think I’m addicted to running AI optimally now 😂
The Edge
I humbly announce that I finally found an edge. I got Qwen3.6-35B-A3B to write systemd scripts for two services that have a non-trivial dependency between them. It failed me three times in a row! I know how simple the scripts can be in spite of the seemingly complex relationship and yet Qwen kept complicating things and ignoring fundamental requirements.
After each time I tweaked some model parameters, I was messing around with temperature and presence penalty, I thought that was the reason why it was failing like this, it wasn’t. Even when I restored original parameters for the last run, it failed again.
Now it’s true that by failure I mean that it didn’t do the task the way it should rather than write something completely incorrect or not runnable, but a failure is a failure.
I switched to DeepSeek V4 Flash and redid the task and it sprinted through it beautifully. Although, it did over-complicate some things too and I had to convince it to simplify.. perhaps it’s just that LLMs aren’t trained well at doing systemd stuff in general and this impacts light models the most. I don’t know.
As for temperature, the moment I drop it to 0.6 (the Qwen recommendation) I start seeing the now all-too-generic OpenAI-style speech and glazing. I felt sick and put the temperature back to 0.7, it’s more straight to the point with minimal glazing. which is W 🏆 but I may be imagining the whole thing lol who knows it’s still an RNG-seed at its heart.
I’ve seen some benchmarks that mainly use mean KL divergence as some sort of measurement of quality, someone posted a graph comparing all popular quants by KL divergence. KLD is not a measurement of objective quality, it’s the mathematical divergence between two distributions of values. It’s particularly not good for MoE models/non-uniform quants as it doesn’t really care about sensitivities of each layer, and I can imagine it’s also not an objective indicator for non-linear quants like IQ4_NL.
Benchmarking LLMs continues to be a very difficult challenge, similar to measuring human intelligence in its subjectivity. Most AI labs understand this and with every release they max their results by selectively tweaking things to make their own model look competitive.
If the model is close and the team just selectively tweaks things to nudge it a few points up, that could be forgiven.. but even totally useless models like Nemotron-3-Ultra (a 550B model btw) hilariously are “presented” as competitive. At this point, you might as well just make the numbers up guys it’s much less work and the whole thing is subjective anyway.
The Hardware
Yesterday I was lurking in r/LocalLlama and I realized that most people there have way better hardware then me with 16-24GB VRAM RTX 5000 series etc, lots of DDR5 RAM, modern processors, etc.. I think I’m the most potato PC there with my 8GB 3070 Ti and 3700X Ryzen.
And yet… they are all describing an approximately similar level of performance for the same models, except with a lot less context? many of them seem to consider tokens per second to be critical but don’t care much about context. So you see someone with a 5080 GPU and double or triple my VRAM but they’re running Qwen3.6 at 64k context only. In the meantime, I have 8GB VRAM and can run average-to-low speed 512k context just fine 🤷
What are they missing here? I already identified that a lot of local LLM enthusiasts treat llama launch arguments as some sort of magic spell and like to dictate every single one, some even boast about running a Q3 quant so an MoE model fits in its entirety in their VRAM… but why? by design MoE models do not need to be in VRAM to get acceptable speeds.
It’s a mystery.
In between dreaming of soon hopefully affording a 128GB Strix Halo or M5 Mac to dedicate to running local models, I realized two things.. there’s not much more that a 128GB VRAM system can do at the moment which is crazy. It can run Qwen3.6 27B that needs to be fully in VRAM for usable generation speed, but that’s ~20GB only so should be perfectly runnable on a 24GB consumer GPU.
At this point I was still on Windows, I’m running APEX-I-Quality/Q4_K_XL quants with 262k context at <27 t/s. I wonder… what can I do to push the token generation speed and my memory limitations even further?
Answer: ditch Windows 11
The Triumphs
Today, I carved out a 160GB partition from my fastest nvme disk, and installed Ubuntu Server 26.04 on it. Kept it very lean. At the end when I got to llama.cpp compilation, the RAM usage was only 800MB total. That and ZERO VRAM used (aside from whatever NVIDIA UEFI driver allocates for the framebuffer which is minuscule).
Then I copied over my models and launchers, and started testing..
- Qwen2.5-coder 7B instruct Q4_K_M (32K): previous best in Win11 was <81 t/s which is actually amazing. Now on Ubuntu? <102 t/s!!! +21 more tees 🚅
- Qwen3.6-35B-A3B APEX-I-Quality (256K): previous best in Win11 was a respectable <27 t/s. Now on Ubuntu, we’re blasting at <35 t/s! +8 more tees 🏃
- Gemma4-26B-A4B Q4_K_M (256K): this one was too slow for me and qwen3.6 is faster and better, I didn’t even benchmark it. Now on Ubuntu, it’s rolling at <29 t/s which makes it actually usable! 🏖️
The next challenge was likely to fail big time.. I wanted to find out if I can actually run both qwen3.6-35b AND qwen2.5-coder 3b. That way I can have a coding agent + my code completion assist setup to run on my coding laptop. How crazy would that be?
And it .. just worked. I started qwen3.6 first, then after about 2 minutes, started qwen2.5 coder. No drama. The reason this worked is that my RAM has around 9GB left over and my CPU has 8 cores/16 threads, for optimal results qwen3.6 uses only 8 threads, so on the remaining idle 8 threads, qwen2.5 ran (100% on CPU of course).
Now, the 3B running on my 3700X CPU? too slow. 14 t/s, that’s below usable for code completions. So I switched to 1.5B, and it ran at 30+ t/s! which is sufficient although dumb as a brick.
Mission Accomplished 🎯
.. with a caveat. If I run inference in both models simultaneously, speed drops into the 20s for both. But that’s ok.
The Failures
There were so many this time.
Several times I found myself wondering whether running Qwen3.6 is somehow worse under Linux and that’s why it’s faster? but then I go on and test on OpenRouter and it fails in the same way, and it’s not the only one that fails that way but much bigger models do too.
Screen
Here’s a simple question that I’ve not seen Qwen3.6-35B-A3B answer correctly in many shots:
Using GNU screen, I want to vertically split the current window, and start bash in the new pane.
It’s very simple. Thing is screen is a bit eccentric on account of being an elder, the new pane after split will be completely blank and you can’t type anything in it. The only way to create a new bash session in that new pane is to switch to the pane via Ctrl+a TAB and then create a new session Ctrl+a c.
Qwen3.6-35B never gets the last part correctly. It always thinks either that screen should have started a bash session by itself so I just need to switch to it (incorrect), or that I have to type “bash” in the new pane which isn’t possible since the pane is blank and there’s no way to type anything in it!
The first time I tried to guide the LLM to the correct answer, it took 4 prompts to get there with the help of a web search tool.
I tried every quant I have for qwen3.6-35b, they all failed the same way. Tweaked temperature and presence panalty, no luck. And even tried the OpenRouter hosted qwen3.6-35b (the paid one). Also failed.
Then I tried Gemma4-26B-A4B out of curiosity. And it failed in exactly the same way..!
Qwen3.6 Plus, DeepSeek V4 Flash, Qwen3.6-27B, all answered correctly.
This might just be an MoE quirk? the dense models appear fine.
Flood Fill
Another example failure I ran into is due to complexity probably. I have a 2D fantasy console I’m working on, and I wanted a pixel flood fill function. Simple and straight forward. Qwen3.6-35B kept failing, most its implementations (out of 5 times I tried) had a bug where the flood fill function enters an infinite loop at random hanging the drawing thread. One failed because the floodfill didn’t look right.
Then I tried Gemma4-26B-A4B (the paid OpenRouter instance), and it failed completely.. it wasn’t able to implement this.
And I find myself again thinking this is a knock against Qwen3.6, and then discovering this is inexplicably difficult even for much larger LLMs!
BigPickle and CoBuddy both failed.
Qwen3.6 Plus and DeepSeek V4 Flash were both hit and miss, more miss than hit.
I stopped testing other models at this point and called in the cavalry, DeepSeek V4 Pro, zero shot, did the job perfectly. I was a minute away from attempting to do it myself (would cost me 0.5-3 hours), I implemented one in assembly when I was 19 lol.
Maybe LLMs aren’t actually as good at leet coding as I thought. I wish topcoder arena was still around, I could pick 10 sample tests of different levels and attempt them with a large group of models. Actually, I just found out they published their archive! A project for another week (it needs a framework that provides tests and validation to confirm correct solutions, original arena app also measured time/memory cost as some challenges placed limits on those).
I like finding the limits as that allows me to better judge when an LLM is a time-saver and when it’s a waste-of-time. In this particular case, there’s a definite moat between frontier models and the rest.
The Completions
In Part 1 I mentioned I was using Continue vscode extension for completions. This was always broken, never got it to work right. Its completions could not even finish the current line I’m typing so I ended up just disabling it out of annoyance.
I accidentally saw there’s an extension for completion made for llama.cpp that didn’t show up near the top when I searched, it’s called llama-vscode and it’s amazingly functional! And very fast. So I use that now. Thanks to whoever made it, that’s exactly what I hoped for.
If I find that: completions are amazingly useful + 1.5B is not great for them = I’ll hook up a second RTX 3070 I have and run the full coder 7B on it. But it’s going to be tricky as I don’t have space in my case for 2 consumer GPUs, and both will have trouble with cooling.
The Solidification
To solidify my Ubuntu AI OS, I created a bunch of systemd tasks, set them to run at init time. And left Ubuntu Server to be the default boot option. This way, I can blindly power on the PC, and exactly 5 minutes later, I have both models ready and waiting on the network.
Eventually, I found myself manually swapping models a lot to test different configs. I already kinda solved this problem when I was on Windows by creating a launcher that reads profiles from a yaml file so all I need is to specify the profile I want, moving this over the Ubuntu side via a shell script written by Qwen, it was too many steps to change profile.
So I got Qwen to build a simple web frontend to track the current state of both models I’m running (coding agent + code completion) and allow me to directly switch profiles from the web page. I’ve been using this for a few days and it’s much more practical.
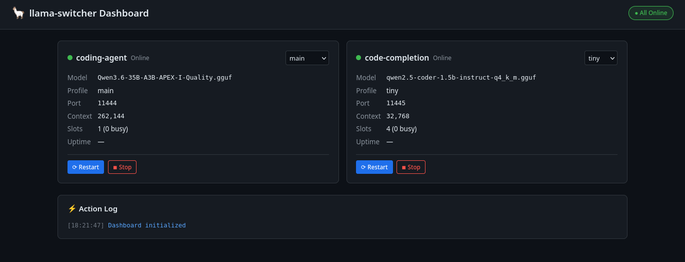
The Benchmarking
Much like with GPUs, I have this desire to benchmark LLMs. I tried the traditional approaches such as using existing benches like BenchLoop, but I wasn’t happy with those as they almost always factor in token generation speed as a huge signal which in my opinion is an L, what’s speed of tokens got to do with model quality?
Eventually I got one specific requirement that needed a benchmark. I wanted to ascertain that for my usecase, mudler’s APEX-I-Quality quant is indeed equivalent or superior to Unsloth’s Q4_K_XL. My feeling was that Q4_K_XL was somehow more stable but APEX was better at coding. Whatever the case might be, it’s more nuanced than A is better than B.
My latest attempt at benchmarking leaned on multi-shot creative-ish tasks and a very simple needle-in-a-haystack test.
The main challenge is based on this cool prompt test that was shared on reddit, and I applied the same marking approach I used when I was a lecturer at a creative/technical university.
Attempts are marked based on: Car, Landscape, Backdrop, and Bonus. Scoring attempt up to a total of 34 points. 3 passing attempts are required for each model configuration to create a range of scores.
All tested Qwen3.6 models use q8_0 KV cache format, and the full 256K context.
Challenge 1: Car
Run the prompt from the reddit post 3 times that produce a usable result:
Write a single HTML file with a full-page canvas and no libraries. Simulate a realistic side-view of a moving car as the main subject. Keep the car visible in the foreground while the background landscape scrolls continuously to create the feeling that the car is driving forward. Use layered scenery for depth: nearby ground, roadside elements, trees, poles, and distant hills or mountains should move at different speeds for a natural parallax effect. Animate the wheels spinning realistically and add subtle body motion so the car feels connected to the road. Let the environment pass smoothly behind it, with repeating but varied scenery that makes the movement feel believable. Use cinematic lighting and a cohesive sky, such as sunset, dusk, or daylight, to enhance atmosphere. The overall motion should feel calm, immersive, and realistic, with a seamless looping animation.
Mark all attempts as submissions to an assignment. If all 3 attempts Pass, the model gets bonus points.
Challenge 2: Needle-In-A-… nvm also Car
I’m 60% certain this is a completely bogus test lol
Two steps to this test:
- Read and summarize a large book that has nothing to do with the coding task
- Change subject and ask it to implement the same Car challenge as above
I used two books downloaded off the Gutenberg library’s newest added books, both from 1800s:
- Brutal test: read and summarize
Number Three Winifred Place by Agnes Gibernewhich reaches 100k tokens context - Cruel test: read and summarize
The Royal Mint its working conduct and operations by George Frederick Ansellwhich reaches 230k tokens context, and is a particularly dense book.
Afterwards, I asked the LLM to write the same car demo from Test 1, which should take less than 10k tokens to do but now on top of significant context build up.
Results of Car
| Model | Variant | Car Test Attempts/Fails | Score Range | Brutal/Cruel |
|---|---|---|---|---|
| Qwen3.6-35B-A3B | APEX-I-Quality | 3/0 | 22 to 32.5 | Pass/Pass, degraded noticeably |
| Qwen3.6-35B-A3B | Q4_K_XL | 4/1 | 15.3 to 27.5 | Pass/Pass, very little degradation |
the 3 attempts at Car:

Last one was the best (scored 29.5) and looked great because of its fast motion:
the 3 attempts at Car:

Second one was the best (scored 27.5). But first one didn’t fully scroll.
Conclusions
So there you have it if this benchmark means anything at all, APEX is noticeably better at coding at least for this creative task (matching what I felt). However, it degrades noticeably with larger context (beyond 100k), this I also knew from experience.
What I didn’t know, is that somehow Q4_K_XL doesn’t seem to degrade noticeably even with a nearly full context (>230k). However, it has a higher tendency for complete failure. The first attempt token generation just stopped for no reason after a few lines of clearly wrong code, the following 3 attempts all passed with good scores.
I also ran the same tests with DeepSeek-V4-Pro, Kimi K2.6, and.. Nemotron-3-Ultra (which came out the week this was written).
Both Kimi K2.6 and DeepSeek-V4 were noticeably better than Qwen3.6 of course, one of K2.6’s attempts achieved the highest score (31 points).
Nemotron-3-Ultra on the other hand? was a joke. Couldn’t produce anything at all due to code syntax errors, its ability to write code appears to be that of a 2 years-old small model which is really bizarre for a 550B LLM from the mega corp that makes all the shovels in 2026 🤦